![]()
Good coding practice
Quote
Code is read more often than it is written.
Guido Van Rossum (author of Python)
It is hard to define exactly what good coding practices are. But the above quote by Guido does hint at what it could be, namely that it has to do with how others observe and perceive your code. In general, good coding practice is about making sure that your code is easy to read and understand, not only by others but also by your future self. The key concept to keep in mind when we are talking about good coding practice is consistency. In many cases it does not matter exactly how you choose to style your code, etc., the important part is that you are consistent about it.
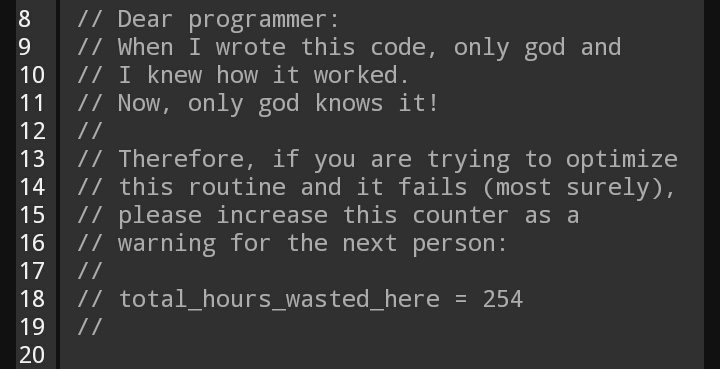
Documentation
Most programmers have a love-hate relationship with documentation: We absolute hate writing it ourselves, but love when someone else has actually taken the time to add it to their code. There is no doubt that well documented code is much easier to maintain, as you do not need to remember all the details about the code to still maintain it. It is key to remember that good documentation saves more time than it takes to write.
The problem with documentation is that there is no right or wrong way to do it. You can end up doing:
-
Under-documentation: You document information that is clearly visible from the code and not the complex parts that are actually hard to understand.
-
Over-documentation: Writing too much documentation will have likely have an effect on most people opposite to what you want: there is too much to read, so people will skip it.
Writing good documentation is a skill that takes time to train, so let's try to do it.
Quote
Code tells you how; Comments tell you why.
Jeff Atwood
❔ Exercises
-
Go over the most complicated file in your project. Be critical and add comments where the logic behind the code is not easily understandable. (1)
-
 In deep learning we often work with multi-dimensional tensors that constantly change shape
after each operation. It is good practice to annotate with comments when tensors undergo some reshaping.
In the following example we compute the pairwise euclidean distance between two tensors using broadcasting
which results in multiple shape operations.
In deep learning we often work with multi-dimensional tensors that constantly change shape
after each operation. It is good practice to annotate with comments when tensors undergo some reshaping.
In the following example we compute the pairwise euclidean distance between two tensors using broadcasting
which results in multiple shape operations.
-
-
Add docstrings to at least two Python functions/methods. You can see here (example 5) a good example of how to use identifiable keywords such as
Parameters,Args,Returns, which standardizes the way of writing docstrings.
Styling
While Python already enforces some styling (e.g. code should be indented in a specific way), this is not enough to ensure that code from different users actually looks similar. Maybe even more troubling is that you will often see that your own style of coding changes as you become more and more experienced. This kind of difference in coding style is not that important to keep in mind when you are working on a personal project, but when multiple people are working together on the same project it is important to consider.
The question then remains what styling you should use. This is where Pep8 comes into play, which is the official style guide for python. It essentially contains what is considered "good practice" and "bad practice" when coding python.
For many years the most commonly used tool to check if your code was PEP8-compliant was to use flake8. However, we are in this course going to be using ruff, which is quickly gaining popularity due to how fast it is and how quickly the developers are adding new features. (1)
- both
flake8andruffare what is called a linter or lint tool, which is any kind of static code analysis program that is used to flag programming errors, bugs, and styling errors.
❔ Exercises
-
Install
ruff. -
Run
ruffon your project or part of your project.Are you PEP8-compliant or are you a mere mortal?
You could go and fix all the small errors that ruff is giving. However, in practice large projects instead rely
on some kind of code formatter that will automatically format your code for you to be PEP8-compliant. Some of the
biggest formatters for the longest time in Python have been black and
yapf, but we are going to use ruff, which also has a built-in formatter that should
be a drop-in replacement for black.
-
Try to use
ruff formatto format your code.
By default ruff will apply a selection of rules when we are either checking it or formatting it. However, many more
rules can be activated through configuration. If you have completed
module M6 on code structure you will have encountered the pyproject.toml file, which can store
both build instructions about our package but also configuration of developer tools. Let's try to configure ruff using
the pyproject.toml file.
-
One aspect that is not covered by PEP8 is how
importstatements in Python should be organized. If you are like most people, you place yourimportstatements at the top of the file and they are ordered simply by when you needed them. A better practice is to introduce some clear structure in our imports. In older versions of this course we have used isort to do the job, but we are here going to configureruffto do the job. In yourpyproject.tomlfile add the following linesand try re-running
ruff checkandruff format. Hopefully this should reorganize your imports to follow common practice. (1)- the common practise is to first list built-in Python packages (like
os) in one block, followed by third-party dependencies (liketorch) in a second block and finally imports from your own package in a third block. Each block is then put in alphabetical order.
-
One PEP8 styling rule that is often diverged from is the recommended line length of 79 characters, which by many (including myself) is considered very restrictive. If your code consists of multiple levels of indentation, you can quickly run into 79 characters being limiting. For this reason many projects increase it, often to 120 characters, which seems to be the sweet spot of how many characters fit in a coding window on a laptop. Add the line
under the
[tool.ruff]section in thepyproject.tomlfile and rerunruff checkandruff formaton your code. -
Experiment with further configuration of
ruff. In particular we recommend adding more rules and looking at[tool.ruff.pydocstyle]configuration to indicate how you have styled your documentation.
Typing
In addition to writing documentation and following a specific styling method, in Python we have a third way of improving
the quality of our code: through typing. Typing goes back to the
earlier programming languages like c, c++ etc. where
data types needed to be explicitly stated for variables:
This is not required by Python but it can really improve the readability of code, since then you can directly read from
the code what the expected types of input arguments and returns are. In Python the : character has been reserved for
type hints. Here is one example of adding typing to a function:
Here we mark that both x and y are integers and using the arrow notation -> we mark that the output type is also
an integer. Assuming that we are also going to use the function for floats and torch.Tensors we could improve the
typing by specifying a union of types. Depending on the version of Python you are using the syntax for this can be
different.
Finally, since this is a very generic function it also works on numpy arrays, etc. We can always default to the Any
type if we are not sure about all the specific types that a function can take.
However, that is basically the same as if our function were not typed, as the type hints do not
help us at all. Therefore, use Any only when necessary.
❔ Exercises
-
We provide a file called
typing_exercise.py. Add typing everywhere in the file. Please note that you will need the following importsfor it to work. This cheat sheet is a good resource on typing. We also provide
typing_exercise_solution.py, but try to solve the exercise yourself.typing_exercise.pySolution
typing_exercise_solution.py 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123
from __future__ import annotations from collections.abc import Callable import torch from torch import nn class Network(nn.Module): """Builds a feedforward network with arbitrary hidden layers. Arguments: input_size: integer, size of the input layer output_size: integer, size of the output layer hidden_layers: list of integers, the sizes of the hidden layers """ def __init__( self, input_size: int, output_size: int, hidden_layers: list[int], drop_p: float = 0.5, ) -> None: super().__init__() # Input to a hidden layer self.hidden_layers = nn.ModuleList([nn.Linear(input_size, hidden_layers[0])]) # Add a variable number of more hidden layers layer_sizes = zip(hidden_layers[:-1], hidden_layers[1:]) self.hidden_layers.extend([nn.Linear(h1, h2) for h1, h2 in layer_sizes]) self.output = nn.Linear(hidden_layers[-1], output_size) self.dropout = nn.Dropout(p=drop_p) def forward(self, x: torch.Tensor) -> torch.Tensor: """Forward pass through the network, returns the output logits.""" for each in self.hidden_layers: x = nn.functional.relu(each(x)) x = self.dropout(x) x = self.output(x) return nn.functional.log_softmax(x, dim=1) def validation( model: nn.Module, testloader: torch.utils.data.DataLoader, criterion: Callable | nn.Module, ) -> tuple[float, float]: """Validation pass through the dataset.""" accuracy = 0 test_loss = 0 for images, labels in testloader: images = images.resize_(images.size()[0], 784) output = model.forward(images) test_loss += criterion(output, labels).item() ## Calculating the accuracy # Model's output is log-softmax, take exponential to get the probabilities ps = torch.exp(output) # Class with highest probability is our predicted class, compare with true label equality = labels.data == ps.max(1)[1] # Accuracy is number of correct predictions divided by all predictions, just take the mean accuracy += equality.type_as(torch.FloatTensor()).mean().item() return test_loss, accuracy def train( model: nn.Module, trainloader: torch.utils.data.DataLoader, testloader: torch.utils.data.DataLoader, criterion: Callable | nn.Module, optimizer: None | torch.optim.Optimizer = None, epochs: int = 5, print_every: int = 40, ) -> None: """Train a PyTorch Model.""" if optimizer is None: optimizer = torch.optim.Adam(model.parameters(), lr=1e-2) steps = 0 running_loss = 0 for e in range(epochs): # Model in training mode, dropout is on model.train() for images, labels in trainloader: steps += 1 # Flatten images into a 784 long vector images.resize_(images.size()[0], 784) optimizer.zero_grad() output = model.forward(images) loss = criterion(output, labels) loss.backward() optimizer.step() running_loss += loss.item() if steps % print_every == 0: # Model in inference mode, dropout is off model.eval() # Turn off gradients for validation, will speed up inference with torch.no_grad(): test_loss, accuracy = validation(model, testloader, criterion) print( f"Epoch: {e + 1}/{epochs}.. ", f"Training Loss: {running_loss / print_every:.3f}.. ", f"Test Loss: {test_loss / len(testloader):.3f}.. ", f"Test Accuracy: {accuracy / len(testloader):.3f}", ) running_loss = 0 # Make sure dropout and grads are on for training model.train() -
mypy is what is called a static type checker. If you are using typing in your code, then a static type checker can help you find common mistakes.
mypydoes not run your code, but it scans it and checks that the types you have given are compatible. Installmypy.Info
An alternative to
mypyis ty developed by the same team asuvandruff.tyis still in beta so may be rough around the edges, but it is also significantly faster thanmypyand will probably be adopted by many projects in the near future. Feel free to trytyinstead ofmypyif you want to. -
Try to run
mypyon thetyping_exercise.pyfileIf you have solved exercise 1 correctly then you should get no errors. If not
mypyshould tell you where your types are incompatible.
🧠 Knowledge check
-
According to PEP8 what is wrong with the following code?
Solution
According to PEP8 classes should follow the CapWords convention, meaning that the first letter in each word of the class name should be capitalized. Thus
myclassshould instead beMyClass. On the other hand, functions and methods should be all lowercase with words separated by underscore. ThusTrainNetworkshould betrain_network. -
What would be the type of argument
xfor a functiondef f(x):if it needs to support the following input:Solution
The easy solution would be to do
def f(x : Any). But instead we could also go with:Alternatively, we could do
because
list,tupleanddictare all iterables and therefore can be covered by one type (in this specific case).
This ends the module on coding style. We again want to emphasize that a good coding style is more about having a consistent style than strictly following PEP8. A good example of this is Google, which has their own style guide for Python. This guide does not match PEP8 exactly, but it makes sure that different teams within Google that are working on different projects are still to a large degree following the same style and therefore if a project is handed from one team to another then at least that will not be a problem.