![]()
Distributed Training
In this module we are going to look at distributed training. Distributed training is one of the key ingredients to all the awesome results that deep learning models are producing. For example: Alphafold the highly praised model from DeepMind that seems to have solved protein structure prediction, was trained in a distributed fashion for a few weeks. The training was done on 16 TPUv3s (specialized hardware), which is approximately equal to 100-200 modern GPUs. This means that training Alphafold without distributed training on a single GPU (probably not even possible) would take a couple of years to train! Therefore, it is simply impossible currently to train some of the state-of-the-art (SOTA) models within deep learning without taking advantage of distributed training.
When we talk about distributed training, there are a number of different paradigms that we may use to parallelize our computations:
- Data parallel (DP) training
- Distributed data parallel (DDP) training
- Sharded training
In this module we are going to look at data parallel training, which is the original way of doing parallel training and distributed data parallel training which is an improved version of data parallel. If you want to know more about sharded training which is the newest of the paradigms you can read more about it in this blog post, which describes how sharded can save over 60% of memory used during your training.
Finally, we want to note that for all the exercises in the module you are going to need a multi-GPU setup. If you have not already gained access to multi GPU machines on GCP (see the quotas exercises in this module) you will need to find another way to do the exercises. For DTU Students I recommend checking out this optional module on using the high performance cluster (HPC) where you can get access to multi-GPU resources.
Data parallel
While data parallel today in general is seen as obsolete compared to distributed data parallel, we are still going to investigate it a bit since it offers the most simple form of distributed computations in a deep learning pipeline.
The figure below shows both the forward and backward steps in the data parallel paradigm.
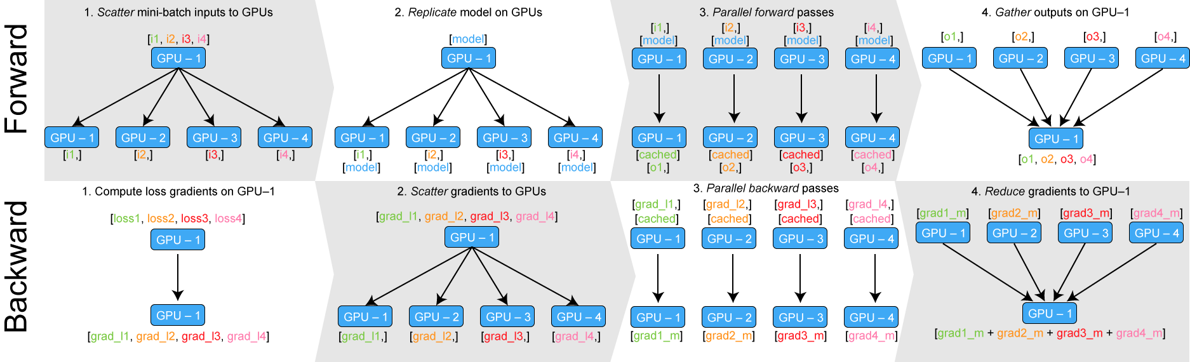
The steps are the following:
-
Whenever we try to do a forward call e.g.
out=model(batch)we take the batch and divide it equally among all devices. If we have a batch size ofNandMdevices each device will be sentN/Mdatapoints. -
Afterwards each device receives a copy of the
model, e.g., a copy of the weights that currently parametrize our neural network. -
In this step we perform the actual forward pass in parallel. This is the actual step that can help us scale our training.
-
Finally we need to send back the output of each replicated model to the primary device.
Similar to the analysis we did of parallel data loading, we cannot always expect that this will actually take less time
than doing the forward call on a single GPU. If we are parallelizing over M devices, we essentially need to do 3xM
communication calls to send batch, model and output between the devices. If the parallel forward call does not outweigh
this, then it will take longer.
In addition, we also have the backward path to focus on.
-
As the end of the forward collected the output on the primary device, this is also where the loss is accumulated. Thus, loss gradients are first calculated on the primary device.
-
Next we scatter the gradient to all the workers.
-
The workers then perform a parallel backward pass through their individual model.
-
Finally, we reduce (sum) the gradients from all the workers on the main process such that we can do gradient descent.
One of the big downsides of using data parallel is that all the replicas are destroyed after each backward call. This means that we over and over again need to replicate our model and send it to the devices that are part of the computations.
Even though it seems like a lot of logic goes into implementing data parallel into your code, in PyTorch we can very simply enable data parallel training by wrapping our model in the nn.DataParallel class.
from torch import nn
model = MyModelClass()
model = nn.DataParallel(model, device_ids=[0, 1]) # data parallel on gpu 0 and 1
preds = model(input) # same as usual
❔ Exercises
Please note that the exercise only makes sense if you have access to multiple GPUs.
-
Create a new script (call it
data_parallel.py) where you take a copy of modelFashionCNNfrom thefashion_mnist.pyscript. Instantiate the model and wraptorch.nn.DataParallelaround it such that it can be executed in data parallel. -
Try to run inference in parallel on multiple devices (pass a batch multiple times and time it):
Does data parallel decrease the inference time? If no, can you explain why that may be? Try playing around with the batch size, and see if data parallel is more beneficial for larger batch sizes.
Distributed data parallel
It should be clear that there is a huge disadvantage to using the data parallel paradigm to scale your applications: the model needs to replicated on each pass (because it is destroyed in the end), which requires a large transfer of data. This is the main problem that distributed data parallel tries to solve.
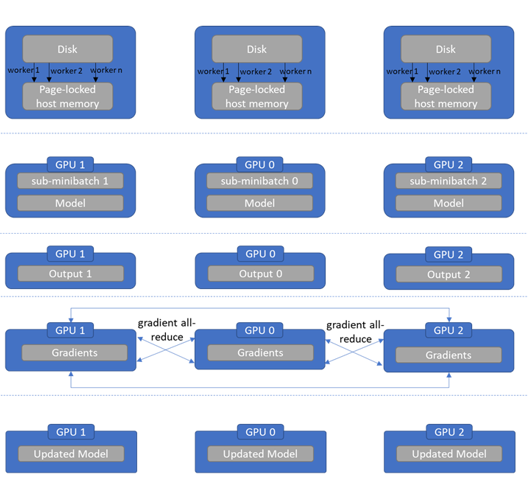
The key difference between distributed data parallel and data parallel is that we move the model update (the gradient step) to happen on each device in parallel instead of only on the main device. This has the consequence that we do not need to replicate the model in each step, instead we just keep a local version on each device that we keep updating. The full set of steps (as shown in the figure):
-
Initialize an exact copy of the model on each device.
-
From disk (or memory) we start by loading data into a section of page-locked host memory per device. Page-locked memory is essentially a way to reserve a piece of a computer's memory for a specific transfer that is going to happen over and over again to speed it up. The page-locked regions are loaded with non-overlapping data.
-
Transfer data from page-locked memory to each device in parallel.
-
Perform a forward pass in parallel.
-
Do an all-reduce operation on the gradients. An all-reduce operation is a so called all-to-all operation meaning that all processes send their own gradient to all other processes and also receive them from all other processes.
-
Reduce the combined gradient signal from all processes and update the individual model in parallel. Since all processes received the same gradient information, all models will still be in sync.
Thus, in distributed data parallel we here end up only doing a single communication call between all processes, compared to all the communication going on in data parallel. While all-reduce is a more expensive operation that many of the other communication operations that we can do, because we only have to do one we gain a huge performance boost. Empirically distributed data parallel tends to be 2-3 times faster than data parallel.
However, this performance increase does not come for free. Where we could implement data parallel in a single line in PyTorch, distributed data parallel is much more involved.
❔ Exercises
-
We have provided an example of how to do distributed data parallel training in PyTorch in the two files
distributed_example.pyanddistributed_example.sh. Your objective is to get an understanding of the necessary components in the script to get this kind of distributed training to work. Try to answer the following questions (HINT: try to Google around):-
What is the function of the
DDPwrapper? -
What is the function of the
DistributedSampler? -
Why is it necessary to call
dist.barrier()before passing a batch into the model? -
What do the different environment variables do in the
.shfile?
-
-
Try to benchmark the runs using 1 and 2 GPUs.
-
The first exercise has hopefully convinced you that it can be quite the trouble writing distributed training applications yourself. Luckily for us,
PyTorch-lightningcan take care of this for us such that we do not have to care about the specific details. To get your model training on multiple GPUs you need to change two arguments in the trainer: theacceleratorflag and thegpusflag. In addition to this, you can read through this guide about any additional steps you may need to do (for many of you, it should just work). Try running your model on multiple GPUs. -
Try benchmarking your training using 1 and 2 gpus, e.g., try running a couple of epochs and measure how long it takes. How much of a speedup can you actually get? Why can you not get a speedup of 2?