![]()
Minimizing boilerplate
Boilerplate is a general term that describes any standardized text, copy, documents, methods, or procedures that may be used over and over again without making major changes to the original. But how does this relate to doing machine learning projects? If you have already tried doing a couple of projects within machine learning you will probably have seen a pattern: every project usually consists of these three aspects of code:
- a model implementation
- some training code
- a collection of utilities for saving models, logging images, etc.
While the latter two certainly seem important, in most cases the actual development or research often revolves around defining the model. In this sense, both the training code and the utilities become boilerplate that should just carry over from one project to another. But the problem is that we usually have not generalized our training code to take care of the small adjustments that may be required in future projects and we therefore end up implementing it over and over again every time we start a new project. This is of course a waste of our time that we should try to find a solution to.
This is where high-level frameworks come into play. High-level frameworks are built on top of another framework (PyTorch in this case) and try to abstract/standardize how to do particular tasks such as training. At first it may seem irritating that you need to comply with someone else's code structure, however there is a good reason for that. The idea is that you can focus on what really matters (your task, model architecture etc.) and do not have to worry about the actual boilerplate that comes with it.
The most popular high-level (training) frameworks within the PyTorch ecosystem are:
They all offer many of the same features, so choosing one over the other for most projects should not matter that much.
We are here going to use PyTorch Lightning, as it offers all the functionality that we are going to need later in the
course.
PyTorch Lightning
In general refer to the documentation from PyTorch lightning
if in doubt about how to format your code for doing specific tasks. We are here going to explain the key concepts of
the API that you need to understand to use the framework, starting with the LightningModule and the Trainer.
LightningModule
The LightningModule is a subclass of a standard nn.Module that basically adds additional structure. In addition to
the standard __init__ and forward methods that need to be implemented in a nn.Module, a LightningModule further
requires two more methods implemented:
-
training_step: should contain your actual training code e.g. given a batch of data this should return the loss that you want to optimize -
configure_optimizers: should return the optimizer that you want to use
Below these two methods are shown added to the standard MNIST classifier
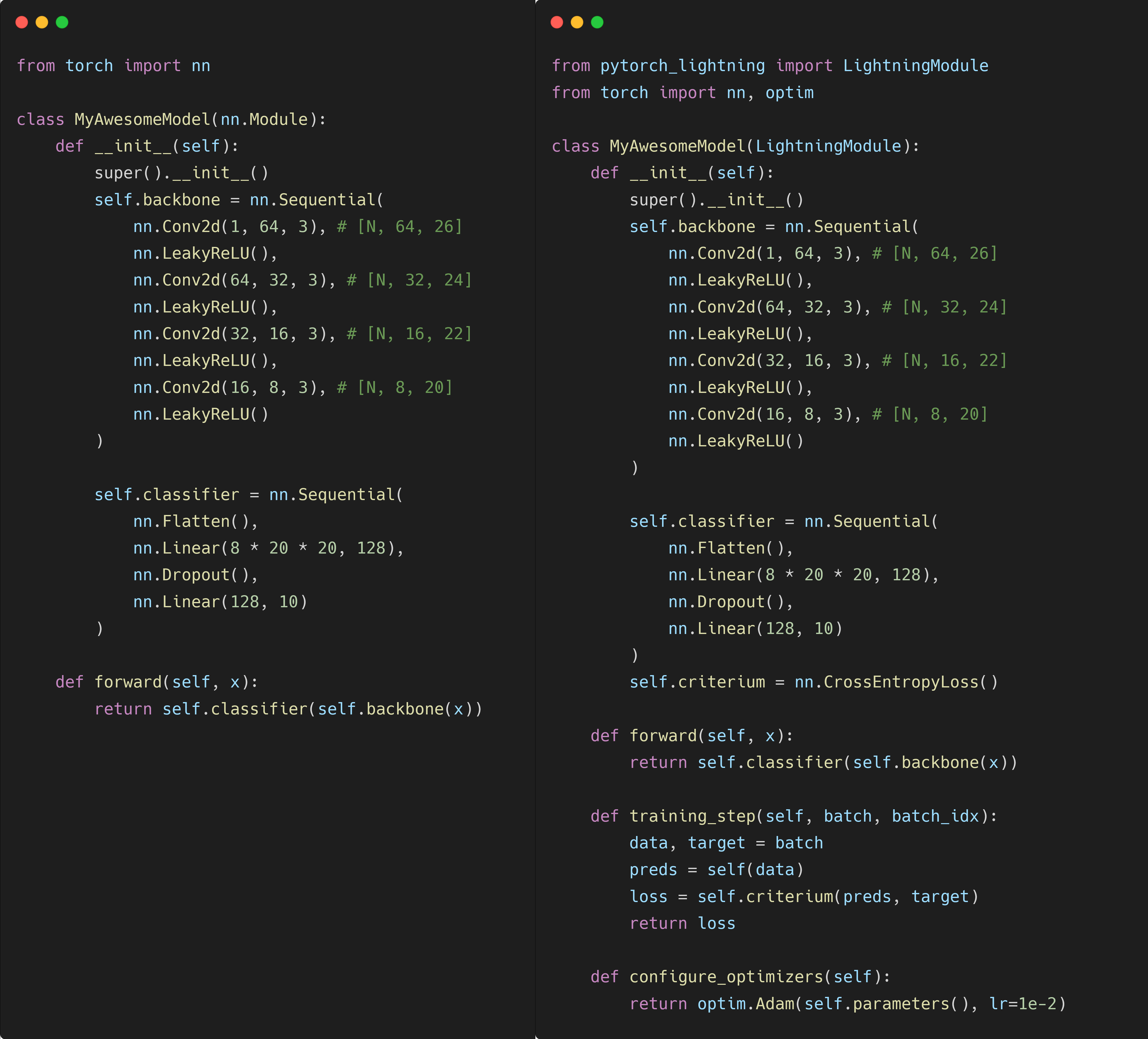
Compared to a standard nn.Module, the additional methods in the LightningModule basically specify exactly how you
want to optimize your model.
Trainer
The second component to lightning is the Trainer object. As the name suggests, the Trainer object takes care of the
actual training, automating everything that you do not want to worry about.
from pytorch_lightning import Trainer
model = MyAwesomeModel() # this is our LightningModule
trainer = Trainer()
traier.fit(model)
That's essentially all that you need to specify in lightning to have a working model. The trainer object does not have methods that you need to implement yourself, but it has a bunch of arguments that can be used to control how many epochs you want to train, if you want to run on gpu, etc. To get the training of our model to work we just need to specify how our data should be fed into the lightning framework.
Data
For organizing our code that has to do with data in Lightning we essentially have three different options. However,
all three assume that we are using torch.utils.data.DataLoader for the data loading.
-
If we already have a
train_dataloaderand possibly also aval_dataloaderandtest_dataloaderdefined we can simply add them to ourLightningModuleusing the similarly named methods: -
Maybe even simpler, we can directly feed such dataloaders into the
fitmethod of theTrainerobject: -
Finally,
Lightningalso has theLightningDataModulethat organizes data loading into a single structure, see this page for more info. Putting data loading into aDataModulemakes sense as it can then be reused between projects.
Callbacks
Callbacks are one way to add additional functionality to your model, that strictly speaking is not already part of your
model. Callbacks should therefore be seen as a self-contained feature that can be reused between projects. You have the
option of implementing callbacks yourself (by inheriting from the pytorch_lightning.callbacks.Callback base class) or
using one of the
built-in callbacks.
Of particular interest are the ModelCheckpoint and EarlyStopping callbacks:
-
The
ModelCheckpointmakes sure to save checkpoints of your model. This is in principal not hard to do yourself, but theModelCheckpointcallback offers additional functionality by saving checkpoints only when some metric improves, or only save the bestKperforming models, etc. -
The
EarlyStoppingcallback can help you prevent overfitting by automatically stopping the training if a certain value is not improving anymore:
Multiple callbacks can be used by passing them all in a list e.g.
❔ Exercises
Please note that in the following exercise we will basically ask you to reformat all your MNIST code to follow the
lightning standard, such that we can take advantage of all the tricks the framework has to offer. The reason we did not
implement our model in lightning to begin with is that to truly understand why it is beneficial to use a high-level
framework to do some of the heavy lifting you need to have gone through some implementation troubles yourself.
-
Install pytorch lightning:
-
Convert your corrupted MNIST model into a
LightningModule. You can either choose to completely overwrite your old model or implement it in a new file. The bare minimum that you need to add while converting to get it working with the rest of lightning:-
The
training_stepmethod. This function should contain essentially what goes into a single training step and should return the loss at the end -
The
configure_optimizersmethod
Please read the documentation for more info.
Solution
-
-
Make sure your data is formatted such that it can be loaded using the
torch.utils.data.DataLoaderobject. -
Instantiate a
Trainerobject. It is recommended to take a look at the trainer arguments (there are many of them) and maybe adjust some of them:-
Investigate what the
default_root_dirflag does. -
As default lightning will run for 1000 epochs. This may be too much (for now). Change this by changing the appropriate flag. Additionally, there is also a flag to set the maximum number of steps that we should train for.
Solution
Setting the
max_epochswill accomplish this.Additionally, you may consider instead setting the
max_stepsflag to limit based on the number of steps ormax_timeto limit based on time. Similarly, the flagsmin_epochs,min_stepsandmin_timecan be used to set the minimum number of epochs, steps or time. -
To start with we also want to limit the amount of training data to 20% of its original size. Which trainer flag do you need to set for this to work?
-
-
Try fitting your model:
trainer.fit(model) -
Now try adding some
callbacksto your trainer. -
The previous module was all about logging in
wandb, so the question is naturally how doeslightningsupport this. Lightning does not only supportwandb, but also many others. Common to all of them is that logging just needs to happen through theself.logmethod in yourLightningModule:-
Add
self.logto your `LightningModule. It should look something like this: -
Add the
wandblogger to your trainerand try to train the model. Confirm that you are seeing the scalars appearing in your
wandbportal. -
self.logdoes sadly only support logging scalar tensors. Luckily, for logging other quantities we can still access the standardwandb.logthrough our model.def training_step(self, batch, batch_idx): ... # self.logger.experiment is the same as wandb.log self.logger.experiment.log({'logits': wandb.Histrogram(preds)})Try doing this by logging something other than scalar tensors.
-
-
Finally, we maybe also want to do some validation or testing. In lightning we just need to add the
validation_stepandtest_stepto our lightning module and supply the respective data in the form of a separate dataloader. Try to at least implement one of them.Solution
Both the validation and test steps can be implemented in the same way as the training step:
def validation_step(self, batch) -> None: data, target = batch preds = self(data) loss = self.criterion(preds, target) acc = (target == preds.argmax(dim=-1)).float().mean() self.log('val_loss', loss, on_epoch=True) self.log('val_acc', acc, on_epoch=True)Two things to note here are that we are setting the
on_epochflag toTruein theself.logmethod. This is because we want to log the validation loss and accuracy only once per epoch. Additionally, we are not returning anything from thevalidation_stepmethod because we do not optimize over the loss. -
(Optional, requires GPU) One of the big advantages of using
lightningis that you do not need to deal with device placement, i.e. calling.to('cuda')everywhere. If you have a GPU, try to set thegpusflag in the trainer. If you do not have one, do not worry, we are going to return to this when we run training in the cloud.Solution
The two arguments
acceleratoranddevicescan be used to specify which devices to run on and how many to run on. For example, to run on a single GPU you can doAs an alternative the accelerator can just be set to
accelerator="auto"to automatically detect the best available device. -
(Optional) As default PyTorch uses
float32for representing floating point numbers. However, research has shown that neural network training is very robust towards a decrease in precision. The great benefit of going fromfloat32tofloat16is that we get approximately half the memory consumption. Try out half-precision training in PyTorch lightning. You can enable this by setting the precision flag in theTrainer.Solution
Lightning supports four different types of mixed precision training (16-bit and 16-bit bfloat) and two types of:
# 16-bit mixed precision (model weights remain in torch.float32) trainer = Trainer(precision="16-mixed", devices=1) # 16-bit bfloat mixed precision (model weights remain in torch.float32) trainer = Trainer(precision="bf16-mixed", devices=1) # 16-bit precision (model weights get cast to torch.float16) trainer = Trainer(precision="16-true", devices=1) # 16-bit bfloat precision (model weights get cast to torch.bfloat16) trainer = Trainer(precision="bf16-true", devices=1) -
(Optional) Lightning also has built-in support for profiling. Check out how to do this using the profiler argument in the
Trainerobject. -
(Optional) Another great feature of Lightning is that it allows for easily defining command line interfaces through the Lightning CLI feature. The Lightning CLI is essentially a drop in replacement for defining command line interfaces (covered in this module) and can also replace the need for config files (covered in this module) for securing reproducibility when working inside the Lightning framework. We highly recommend checking out the feature and that you try to refactor your code such that you do not need to call
trainer.fitanymore but it is instead directly controlled from the Lightning CLI. -
Free exercise: Experiment with what the lightning framework is capable of. Either try out more of the trainer flags, some of the other callbacks, or maybe look into some of the other methods that can be implemented in your lightning module. Only your imagination is the limit!
That covers everything for today. It has been a mix of topics that should all help you write "better" code (by some objective measure). If you want to deep dive more into the PyTorch lightning framework, we highly recommend looking at the different tutorials in the documentation that cover more advanced models and training cases. Additionally, we also want to highlight other frameworks in the lightning ecosystem:
- Torchmetrics: collection of machine learning metrics written in PyTorch
- lightning flash: high-level framework for fast prototyping, baselining, finetuning with an even simpler interface than lightning
- lightning-bolts: Collection of SOTA pretrained models, model components, callbacks, losses and datasets for testing out ideas as fast as possible