Reproducibility
-

Learn how to create reproducible computing environments using
dockerand how to use them to run your code. -

Learn how to use
hydrato manage configuration files and how to integrate them into your code.
Today is all about reproducibility - one of those concepts that everyone agrees is very important and something should
be done about, but the reality is that it is very hard to ensure complete reproducibility. The last sessions have already
touched a bit on how tools like conda and code organization can help make code more reproducible. Today we are going
all the way to ensure that our scripts and our computing environment are fully reproducible.
Why does reproducibility matter
Reproducibility is closely related to the scientific method:
Observe -> Question -> Hypotheses -> Experiment -> Conclude -> Result -> Observe -> ...
Not having reproducible experiments essentially breaks the cycle between doing experiments and making conclusions. If experiments are not reproducible, then we do not expect that others will arrive at the same conclusion as ourselves. As machine learning experiments are fundamentally the same as doing chemical experiments in a laboratory, we should be equally careful in making sure our environments are reproducible (think of your laptop as your laboratory).
Secondly, if we focus on why reproducibility matters especially in machine learning, it is part of the bigger challenge of making sure that machine learning is trustworthy.
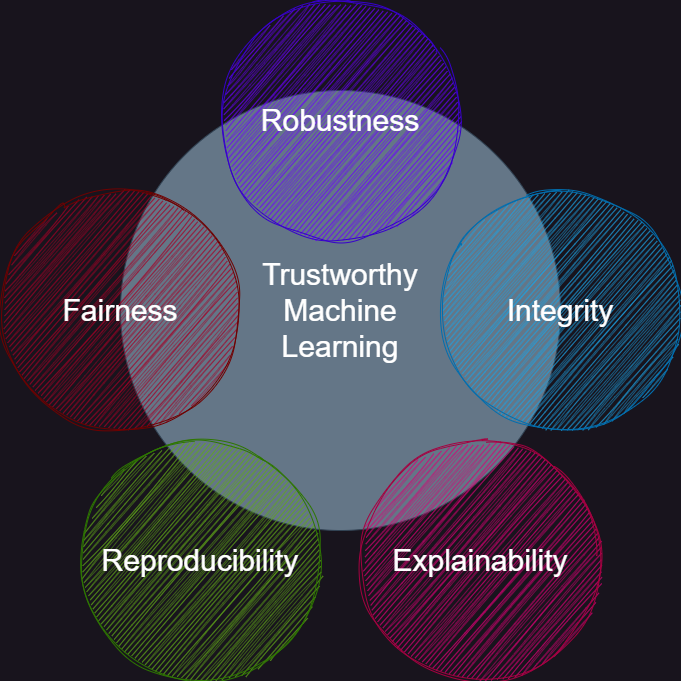
Trustworthy ML is the idea that machine learning agents can be trusted. Take the example of a machine learning agent being responsible for medical diagnoses. It is very clear that we need to be able to trust that the agent gives us the correct diagnosis for the system to work in practice. Reproducibility plays a big role here, because without it we cannot be sure that the same agent deployed at two different hospitals will give the same diagnosis (given the same input).
Learning objectives
The learning objectives of this session are:
- Understand the importance of reproducibility in computer science
- Be able to use
dockerto create a reproducible container, including how to build them from scratch - Understand different ways of configuring your code and how to use
hydrato integrate with config files