![]()
Distributed Data Loading
Core Module
One way that deep learning fundamentally changed the way we think about data in machine learning is that more data is always better. This was very much not the case with more traditional machine learning algorithms (random forest, support vector machines, etc.) where a plateau in performance was often reached for a certain amount of data and did not improve if more was added. However, as deep learning models have become deeper and deeper, more and more data-hungry performance seems to be ever-increasing or at least not reaching a plateau in the same way as for traditional machine learning.
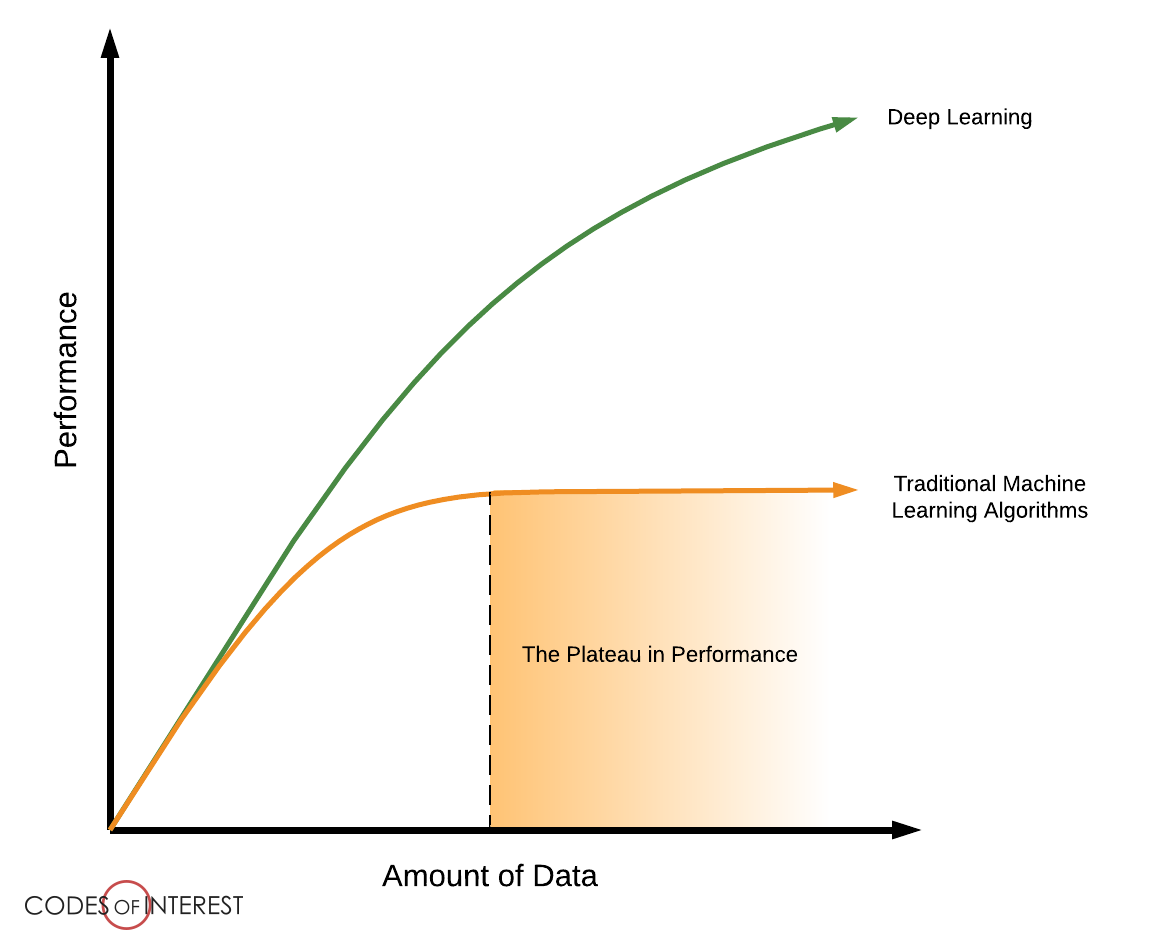
As we are trying to feed more and more data into our models, the obvious first question to ask is how to do this efficiently. As a general rule of thumb, we want the performance bottleneck to be the forward/backward, e.g. the actual computation in our neural network and not the data loading. By bottleneck, we here refer to the part of our pipeline that is restricting how fast we can process data. If data loading is our bottleneck, then our compute device can sit idle while waiting for data to arrive, which is both inefficient and costly. For example, if you are using a cloud provider for training deep learning models, you are paying by the hour per device, and thus not using them fully can be costly in the long run.
In the first set of exercises, we are therefore going to focus on distributed data loading, i.e., how to load data in parallel to make sure that we always have data ready for our compute devices. We are in the following going to look at what is going on behind the scenes when we use PyTorch to parallelize data loading.
A closer look at Data loading
Before we talk distributed applications it is important to understand the physical layout of a standard CPU (the brain of your computer).
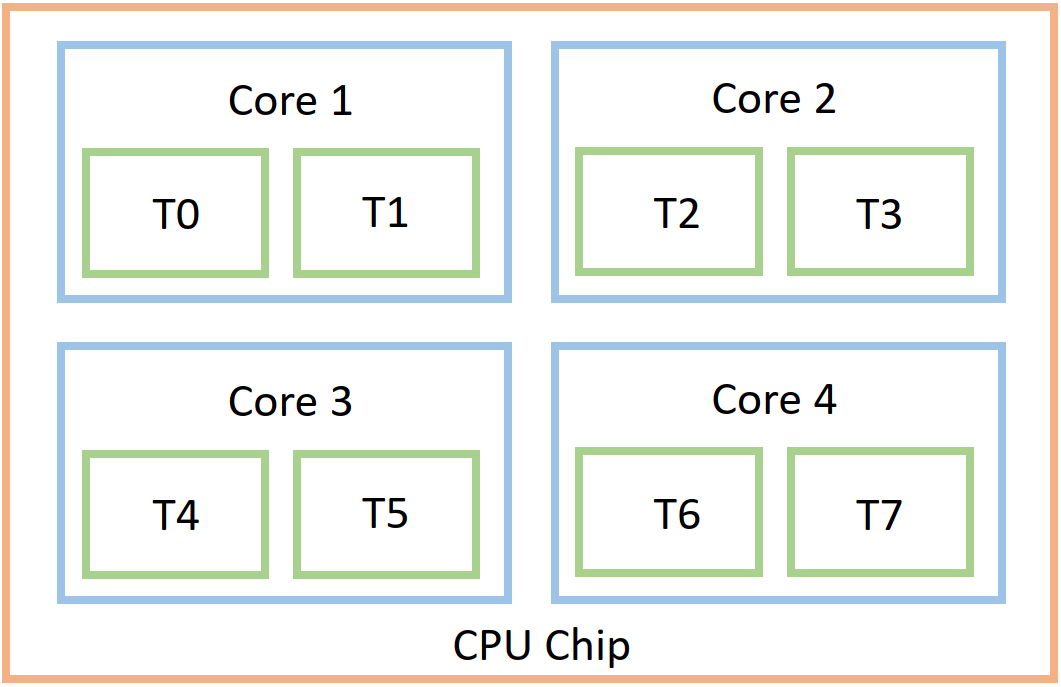
Most modern CPUs are a single chip that consists of multiple cores. Each core can further be divided into threads. In most laptops, the core count is 4 and there are commonly 2 threads per core. This means that the common laptop has 8 threads. The number of threads a compute unit has is important because that directly corresponds to the number of parallel operations that can be executed, i.e., one per thread. In a Python terminal you should be able to get the number of cores in your machine by writing (try it):
import multiprocessing
cores = multiprocessing.cpu_count()
print(f"Number of cores: {cores}, Number of threads: {2*cores}")
A distributed application is in general any kind of application that parallelizes some or all of its workload.
In these exercises we focus only on distributed data loading, which happens primarily only on the CPU. In PyTorch it
is easy to parallelize data loading if you are using their dataset/data loader interface:
from torch.utils.data import Dataset, DataLoader
class MyDataset(Dataset):
def __init__(self, ...):
# whatever logic is needed to init the data set
self.data = ...
def __getitem__(self, idx):
# return one item
return self.data[idx]
dataset = MyDataset()
dataloader = Dataloader(
dataset,
batch_size=8,
num_workers=4 # this is the number of threads we want to parallelize workload over
)
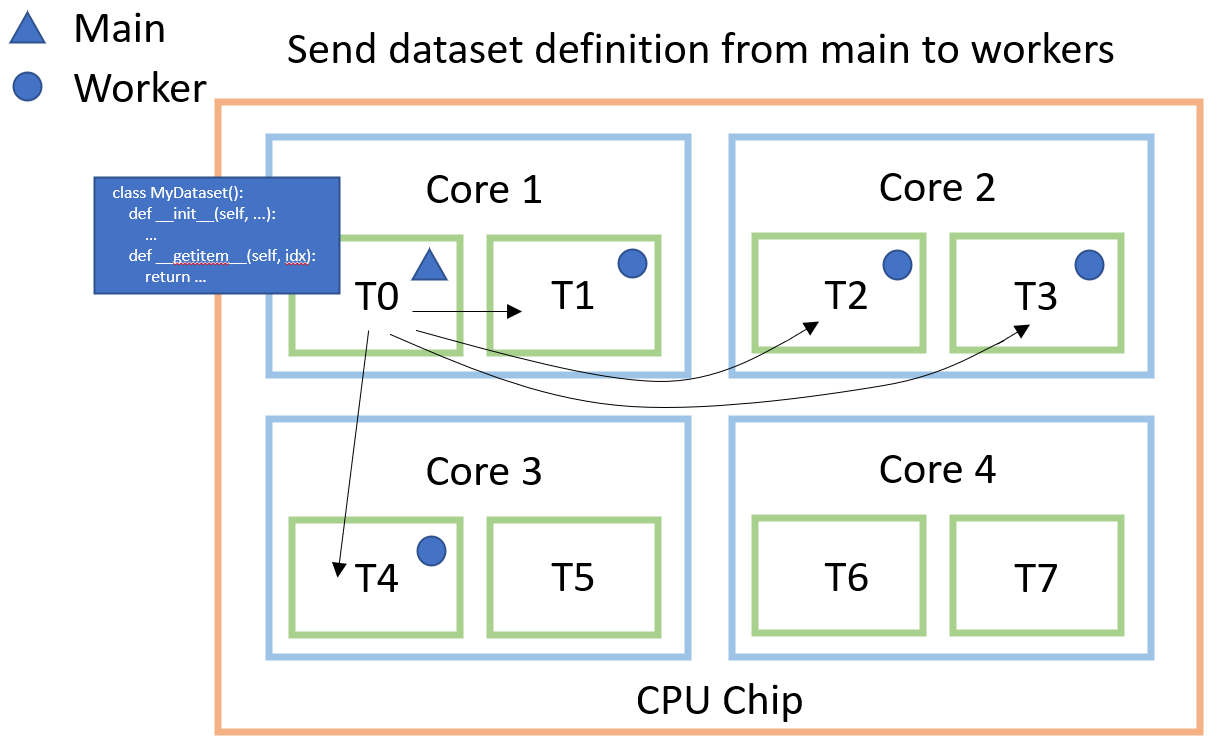
Let's take a deep dive into what happens when we request a batch from our dataloader e.g. next(dataloader). First,
we must understand that we have a thread that plays the role of the main and the remaining threads (in the above
example we request 4) are called workers. When the dataloader is created, we create this structure and make sure that
all threads have a copy of our dataset definition so each can call the __getitem__ method.
Then comes the actual part where we request a batch of data. Assume that we have a batch size of 8 and we do not do
any shuffling. In this step, the master thread then distributes the list of requested data points ([0,1,2,3,4,5,6,7])
to the four worker threads. With 8 indices and 4 workers, each worker will receive 2 indices.
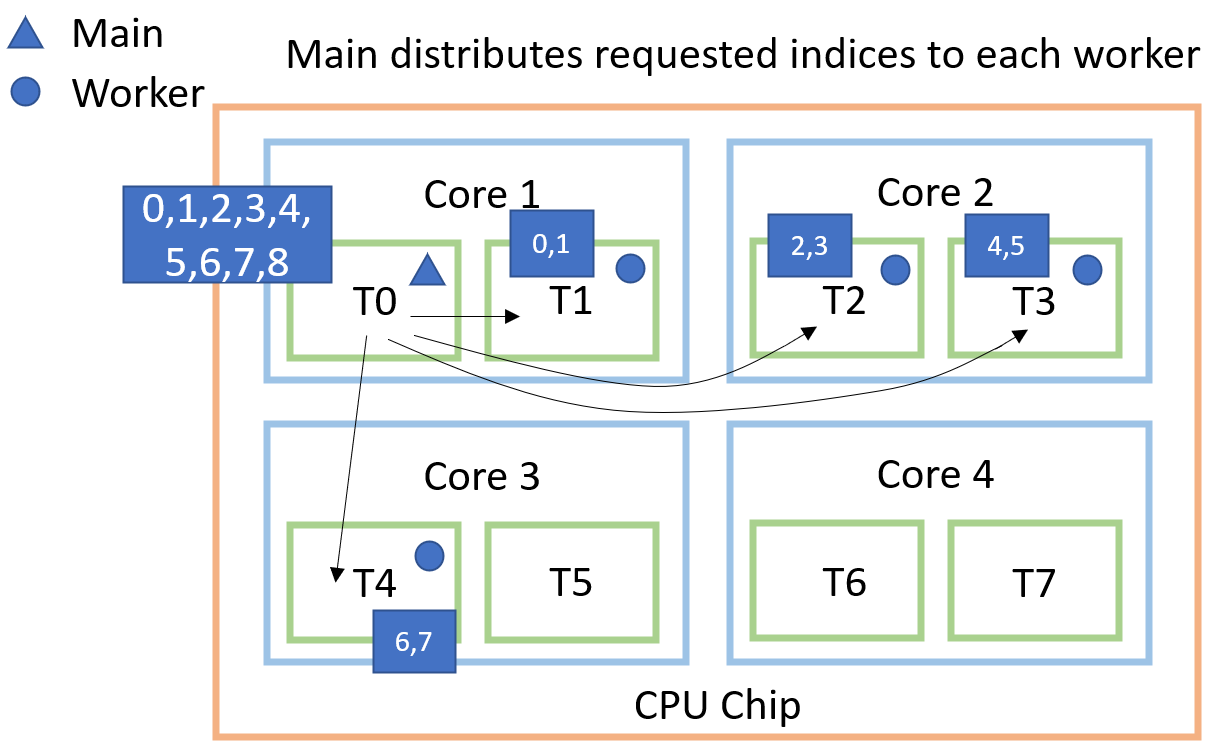
Each worker thread then calls the __getitem__ method for all the indices it has received. When all processes are done,
the loaded images get sent back to the master thread and collected into a single structure/tensor.
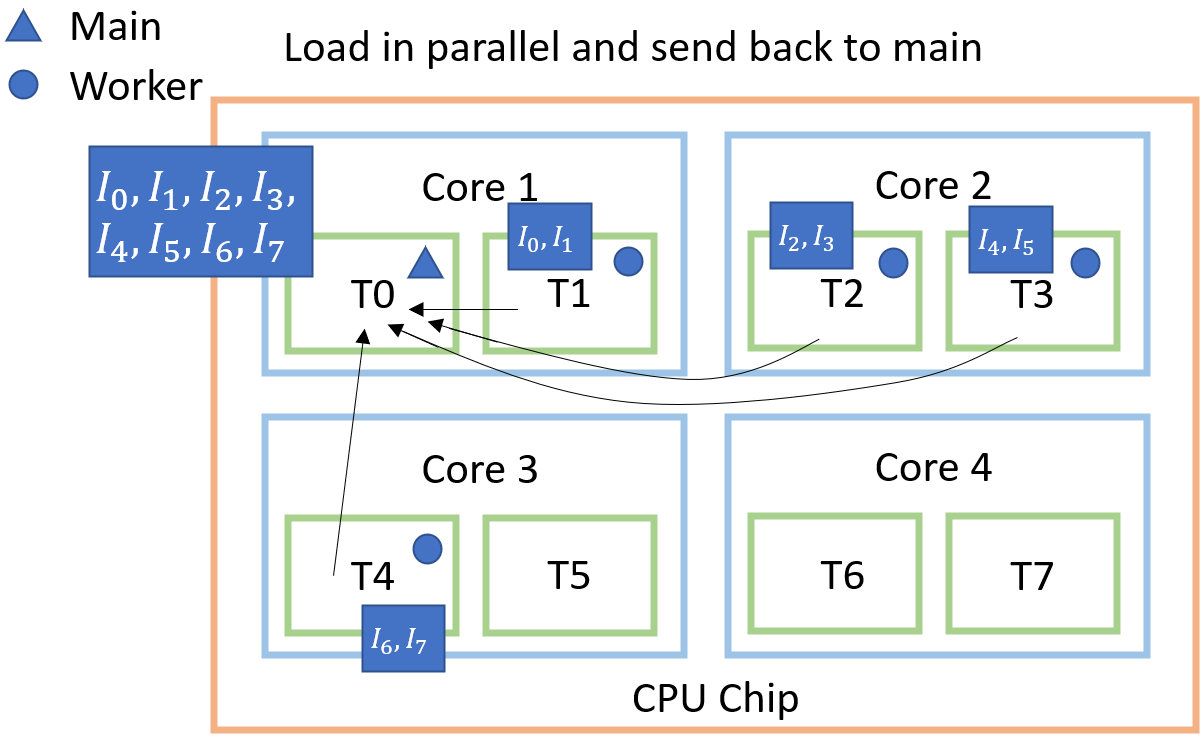
Each arrow corresponds to a communication between two threads, which is not a free operation. In total to get a
single batch (not counting the initial startup cost) in this example we need to do 8 communication operations. This may
seem like a small price to pay, but that may not be the case. If the processing time of __getitem__ is very low (
data is stored in memory, we just need to index to get it) then it does not make sense to use multiprocessing. The
computational savings by doing the look-up operations in parallel are smaller than the communication cost there is
between the main thread and the workers. Multiprocessing makes sense when the processing time of __getitem__ is high
(data is probably stored on the hard drive).
It is this trade-off that we are going to investigate in the exercises.
❔ Exercises
This exercise is intended to be done on the labeled faces in the wild (LFW) dataset. The dataset consists of images of famous people extracted from the internet. The dataset had been used to drive the field of facial verification, which you can read more about in this deep face recognition guide. We are going to imagine that this dataset cannot fit in memory, and your job is therefore to construct a data pipeline that can be parallelized based on loading the raw data files (.jpg) at runtime.
-
Download the dataset and extract it to a folder. It does not matter if you choose the non-aligned or aligned version of the dataset.
-
We provide the
lfw_dataset.pyfile where we have started the process of defining a data class. Fill out__init__,__len__and__getitem__. Note that__getitem__expects that you return a singleimgwhich should be atorch.Tensor. Loading should be done using PIL Image, asPILimages are the default input format for torchvision for transforms (for data augmentation). -
Make sure that the script runs without any additional arguments.
-
Visualize a single batch by filling out the codeblock after the first TODO right after defining the dataloader. The visualization should show when launching the script as
Hint: this tutorial.
-
Explore how the number of workers influences the performance. We have already provided code that will pass over 100 batches from the dataset 5 times and calculate how long it took, which you can play around with by calling
Make an errorbar plot with the number of workers along the x-axis and the timing along the y-axis. The errorbars should correspond to the standard deviation over the 5 runs. HINT: if it is taking too long to evaluate, measure the time over fewer batches (set the
-batches_to_checkflag). Also if you are not seeing any improvement, try increasing the batch size (since data loading is parallelized per batch).For certain machines like the Mac with M1 chipset it is necessary to set the
multiprocessing_contextflag in the dataloder to"fork". This essentially tells the dataloader how the worker nodes should be created. -
Retry the experiment where you change the data augmentation to be more complex:
lfw_trans = transforms.Compose([ transforms.RandomAffine(5, (0.1, 0.1), (0.5, 2.0)), # add more transforms here transforms.ToTensor() ])By making the augmentation more computationally demanding, it should be easier to get a boost in performance when using multiple workers because the data augmentation is also executed in parallel.
-
(Optional, requires access to GPU) If your dataset fits in GPU memory it is beneficial to set the
pin_memoryflag toTrue. By setting this flag we are essentially telling PyTorch that it can lock the data in place in memory which will make the transfer between the host (CPU) and the device (GPU) faster.
This ends the module on distributed data loading in PyTorch. If you want to go into more details we highly recommend that you read this paper that goes into great detail on analyzing how data loading in PyTorch works and performance benchmarks.