![]()
Scalable Inference
Inference is the task of applying our trained model to some new and unseen data, often called prediction. Thus, scaling inference is different from scaling data loading and training, mainly due to inference normally only using a single data point (or a few). As we can neither parallelize the data loading nor parallelize using multiple GPUs (at least not in any efficient way), this is of no use to us when we are doing inference. Additionally, performing inference is often not something we do on machines that can perform large computations, as most inference today is actually either done on edge devices, e.g. mobile phones or in low-cost-low-compute cloud environments. Thus, we need to be smarter about how we scale inference than just throwing more computing power at it.
In this module, we are going to look at various ways that you can either reduce the size of your model or make your model faster. Both are important for running inference fast regardless of the setup you are running your model on. We want to note that this is still very much an active area of research and therefore best practices for what to do in a specific situation can change.
Choosing the right architecture
Assume you are starting a completely new project and have to come up with a model architecture for doing this. What is your strategy? The common way to do this is to look at prior work on similar problems that you are facing and either directly choose the same architecture or create some slight variation hereof. This is a great way to get started, but the architecture that you end up choosing may be optimal in terms of performance but not inference speed.
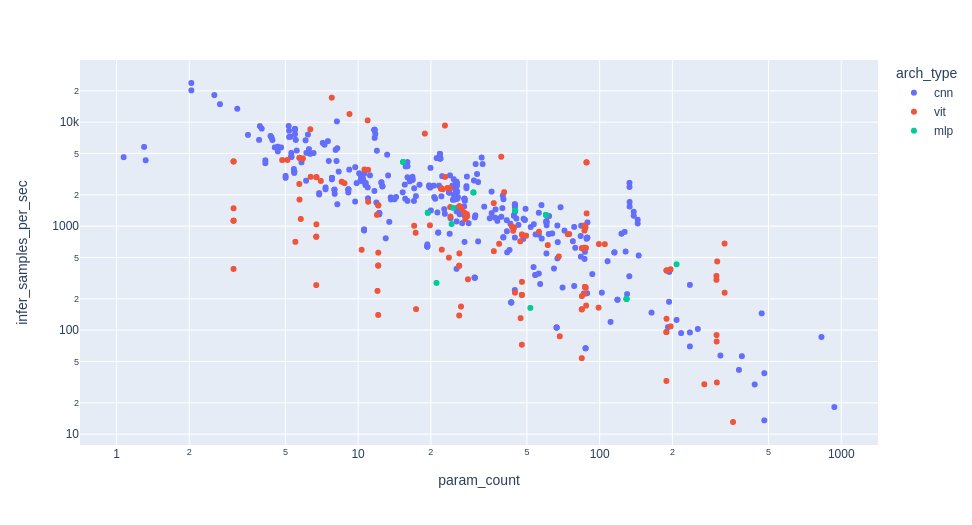
The fact is that not all base architectures are created equal, and a 10K parameter model with one architecture can have a significantly different inference speed than another 10K parameter model with another architecture. For example, consider the figure below which compares a number of models from the timm package, colored based on their base architecture. The general trend is that the number of images that can be processed by a model per sec (y-axis) is inversely proportional to the number of parameters (x-axis). However, we in general see that convolutional base architectures (conv) are more efficient than transformer (vit) for the same parameter budget.
❔ Exercises
As discussed in this blogpost the largest increase in inference speed you will see (given some specific hardware) is choosing an efficient model architecture. In the exercises below we are going to investigate the inference speed of different architectures.
-
Start by checking out this table which contains a list of pretrained weights in
torchvision. Try finding- Efficient net
- Resnet
- Transformer based
models that have in the range of 20-30 million parameters.
-
Write a small script that first initializes all models, creates a dummy input tensor of shape [100, 3, 256, 256] and then measures the time it takes to do a forward pass on the input tensor. Make sure to do this multiple times to get a good average time.
Solution
In this solution, we have chosen to use the efficientnet b5 (30.4M parameters), resnet50 (25.6M parameters) and the swin v2 transformer tiny (28.4M parameters) models.
import time import torch from torchvision import models model_list = ["efficientnet_b5", "resnet50", "swin_v2_t"] image = torch.randn(100, 3, 256, 256) n_reps = 10 for i, m in enumerate(model_list): model = models.get_model(m) tic = time.time() for _ in range(n_reps): _ = model(image) toc = time.time() print(f"Model {i} took: {(toc - tic) / n_reps}") -
Do the results make sense? Based on the above figure we would expect that efficientnet is faster than resnet, which is faster than the transformer based model. Is this also what you are seeing?
-
To figure out why one net is more efficient than another we can try to count the operations each network needs to perform for inference. An operation here we can define as a FLOP (floating point operation) which is any mathematical operation (such as +, -, *, /) or assignment that involves floating-point numbers. Luckily for us someone has already created a python package for calculating this in pytorch: ptflops
-
Install the package.
-
Try calling the
get_model_complexity_infofunction from theptflopspackage on the networks from the previous exercise. What are the results?Solution
from ptflops import get_model_complexity_info import time import torch from torchvision import models model_list = ["efficientnet_b5", "resnet50", "swin_v2_t"] for model in model_list: macs, params = get_model_complexity_info( models.get_model(model_list[0]), (3, 256, 256), backend='pytorch', print_per_layer_stat=False ) print(f"Model {model} have {params} parameters and uses {macs}")
-
-
In the table from the initial exercise, you could also see the overall performance of each network on the Imagenet-1K dataset. Given this performance, the inference speed, the flops count, what network would you choose to use in a production setting? Discuss when choosing one over another should be considered.
Quantization
Quantization is a technique where all computations are performed with integers instead of floats. We are essentially taking all continuous signals and converting them into discretized signals.
As discussed in this
blogpost series,
while float (32-bit) is the primarily used precision in machine learning because it strikes a good balance between
memory consumption, precision and computational requirements, it does not mean that during inference we can't take
advantage of quantization to improve the speed of our model. For instance:
-
Floating-point computations are slower than integer operations.
-
Recent hardware have specialized hardware for doing integer operations.
-
Many neural networks are actually not bottlenecked by how many computations they need to do but by how fast we can transfer data, e.g. the memory bandwidth and cache of your system is the limiting factor. Therefore working with 8-bit integers vs. 32-bit floats means that we can approximately move data around 4 times as fast.
-
Storing models in integers instead of floats saves us approximately 75% of the ram/harddisk space whenever we save a checkpoint. This is especially useful in relation to deploying models using docker (as you hopefully remember) as it will decrease the size of our docker images.
But how do we convert between floats and integers in quantization? In most cases we often use a linear affine quantization:
$$ x_{int} = \text{round}\left( \frac{x_{float}}{s} + z \right) $$
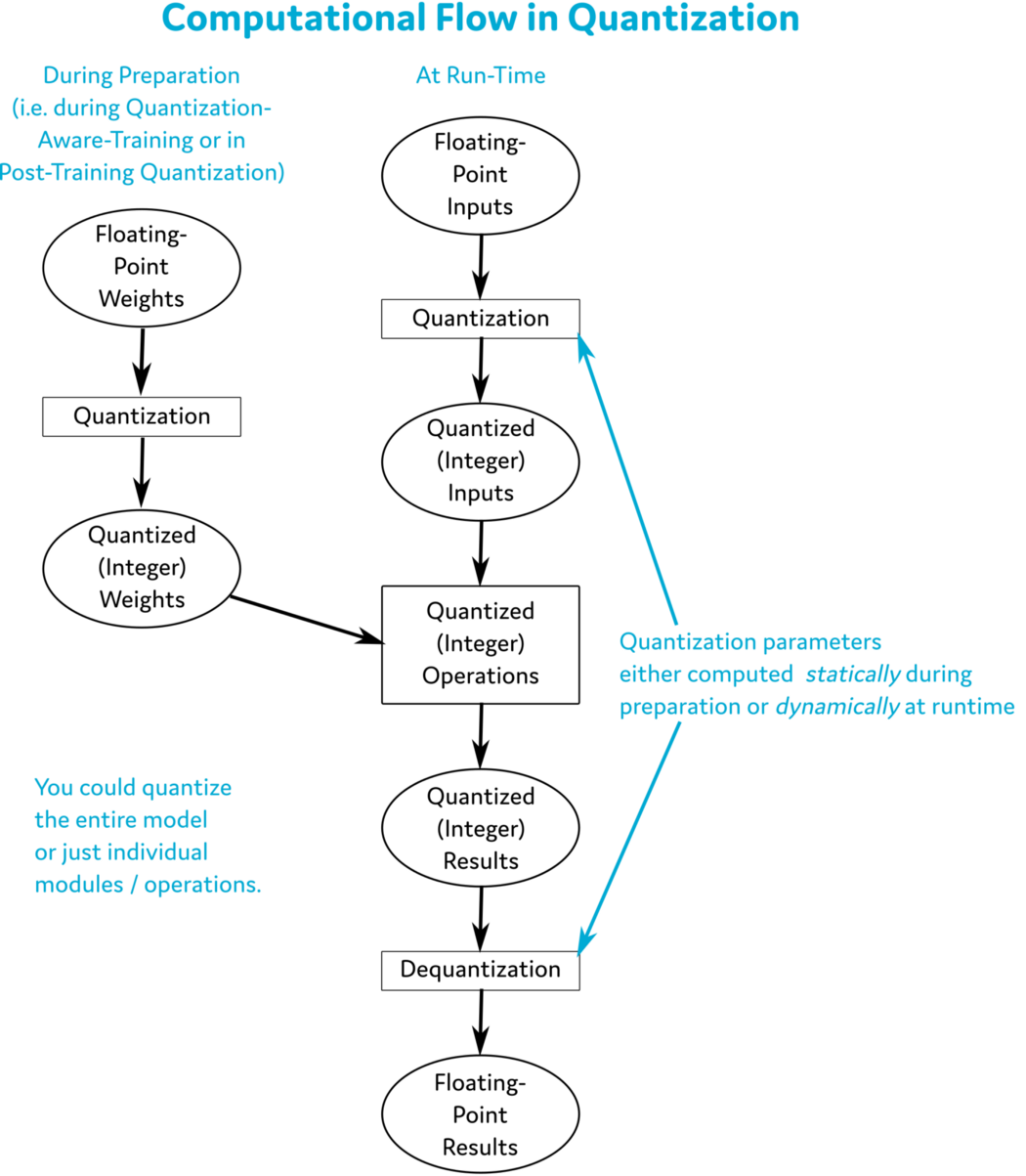
where $s$ is a scale and $z$ is the so-called zero point. But how does that relate to doing inference in a neural network? The figure below shows all the conversations that we need to make to our standard inference pipeline to actually do computations in quantized format.
❔ Exercises
-
Let's look at how quantized tensors look in PyTorch.
-
Start by creating a tensor that contains both random numbers.
-
Next call the
torch.quantize_per_tensorfunction on the tensor. What does the quantized tensor look like? How do the values relate to thescaleandzero_pointarguments? -
Finally, try to call the
.dequantize()method on the tensor. Do you get a tensor back that is close to what you initially started out with?
-
-
As you hopefully saw in the first exercise we are going to perform a number of rounding errors when doing quantization and naively we would expect that these would accumulate and lead to a much worse model. However, in practice we observe that quantization still works, and we actually have a mathematically sound reason for this. Can you figure out why quantization still works with all the small rounding errors? HINT: it has to do with the central limit theorem
-
Let's move on to quantization of our model. Follow this tutorial from PyTorch on how to do quantization. The goal is to construct a model
model_fc32that works on normal floats and a quantized versionmodel_int8. For simplicity you can just use one of the models from the tutorial. -
Let's try to benchmark our quantized model and see if all the trouble that we went through actually paid off. Also try to perform the benchmark on the non-quantized model and see if you get a difference. If you do not get an improvement, explain why that may be.
Pruning
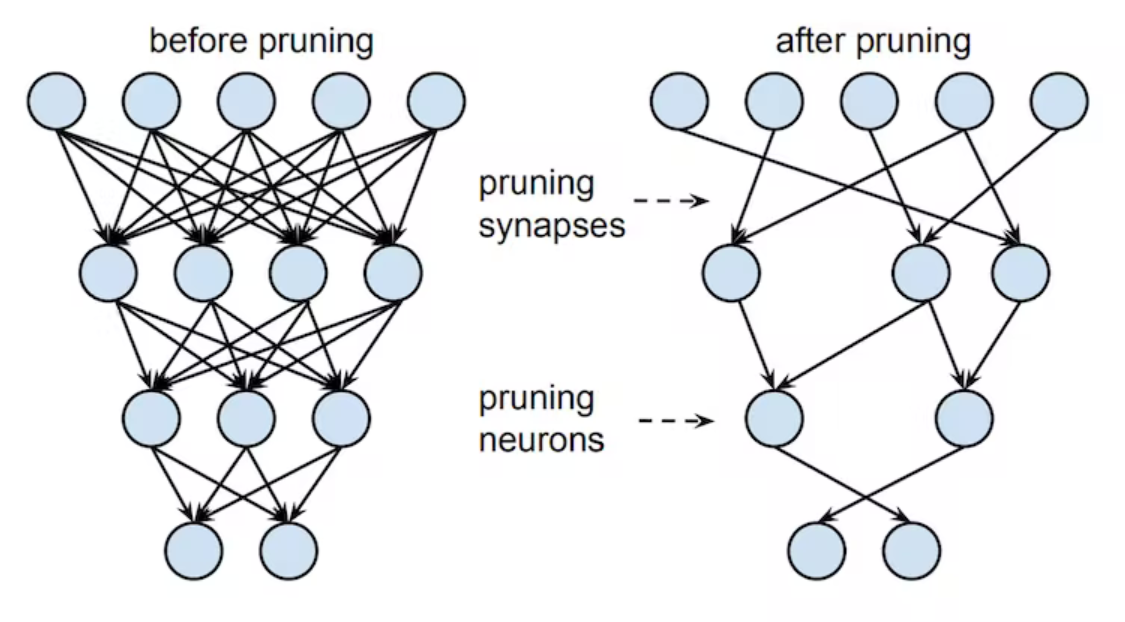
Pruning is another way to reduce the model size and maybe improve the performance of our network. As the figure below illustrates, in pruning we are simply removing weights in our network that we do not consider important for the task at hand. By removing, we here mean that the weight gets set to 0. There are many ways to determine if a weight is important but the general rule is that the importance of a weight is proportional to the magnitude of a given weight. This intuitively makes sense, since weights in all linear operations (fully connected or convolutional) are always multiplied by the incoming value, thus a small weight means a small outgoing activation.
❔ Exercises
-
We provide a start script that implements the famous LeNet in this file. Open and run it just to make sure that you know the network.
-
PyTorch already has some pruning methods implemented in its package. Import the
prunemodule fromtorch.nn.utilsin the script. -
Try to prune the weights of the first convolutional layer by calling.
 You can read about the prune method
in the PyTorch pruning documentation.
You can read about the prune method
in the PyTorch pruning documentation.
Try printing
named_parametersandnamed_buffersbefore and after the module is pruned. Can you explain the difference and what the connection is to themodule_1.weightattribute? -
Try pruning the bias of the same module this time using the
l1_unstructuredfunction from the pruning module. Again check thenamed_parametersandnamed_buffersarguments to make sure you understand the difference between L1 pruning and unstructured pruning. -
Instead of pruning only a single module in the model let's try pruning the whole model. To do this we just need to iterate over all
named_modulesin the model like this:for name, module in new_model.named_modules(): prune.l1_unstructured(module, name='weight', amount=0.2)But what if we wanted to apply different pruning to different layers? Implement a pruning scheme where
- The weights of convolutional layers are L1 pruned with
amount=0.2 - The weights of linear layers are unstructured pruned with
amount=0.4
Print
print(dict(new_model.named_buffers()).keys())after the pruning to confirm that all weights have been correctly pruned. - The weights of convolutional layers are L1 pruned with
-
The pruning we have looked at until now has only been local in nature, i.e., we have applied the pruning independently for each layer, not accounting globally for how much we should actually prune. As you may realize this can quickly lead to a network that is pruned too much. Instead, the more common approach is to prune globally where we remove the smallest
Xamount of connections:-
Start by creating a tuple over all the weights with the following format:
parameters_to_prune = ( (model.conv1, 'weight'), # fill in the rest of the modules yourself (model.fc3, 'weight'), )The tuple needs to have length 5. Challenge: Can you construct the tuple using
forloops, such that the code works for arbitrary-size networks? -
Next prune using the
global_unstructuredfunction to globally prune the tuple of parameters. -
Check that the amount that has been pruned is actually equal to the 20% specified in the pruning. We provide the following function that for a given submodule (for example
model.conv1) computes the number of pruned weights.
-
-
With a pruned network we really want to see if all our effort actually resulted in a network that is faster and/or smaller in memory. Do the following to the globally pruned network from the previous exercises:
-
First we need to make the pruning of our network permanent. Right now it is only semi-permanent as we are still keeping a copy of the original weights in memory. Make the change permanent by calling
prune.removeon every pruned module in the model. Hint: iterate over theparameters_to_prunetuple. -
Next try to measure the time of a single inference (repeated 100 times) for both the pruned and non-pruned networks.
import time tic = time.time() for _ in range(100): _ = network(torch.randn(100, 1, 28, 28)) toc = time.time() print(toc - tic)Is the pruned network actually faster? If not, can you explain why?
-
Next let's measure the size of our network (called
pruned_network) and a freshly initialized network (callednetwork):torch.save(pruned_network.state_dict(), 'pruned_network.pt') torch.save(network.state_dict(), 'network.pt')Look up the size of each file. Is the pruned network actually smaller? If not, can you explain why?
-
Repeat the last exercise, but this time start by converting all pruned weights to sparse format first by calling the
.to_sparse()method on each pruned weight. Is the saved model smaller now?
-
This ends the exercises on pruning. As you probably realized in the last couple of exercises, pruning does not guarantee speedups out of the box. This is because linear operations in PyTorch do not handle sparse structures out of the box. To actually get speedups we would need to deep dive into the sparse tensor operations, which again does not even guarantee a speedup because the performance of these operations depends on the sparsity structure of the pruned weights. Investigating this is out of scope for these exercises, but we highly recommend checking it out if you are interested in sparse networks.
Knowledge distillation
Knowledge distillation is somewhat similar to pruning in the sense that it tries to find a smaller model that can perform equally well as a large model, however it does so in a completely different way. Knowledge distillation is a model compression technique that builds on the work of Bucila et al. in which we try to distill/compress the knowledge of a large complex model (also called the teacher model) into a simpler model (also called the student model).
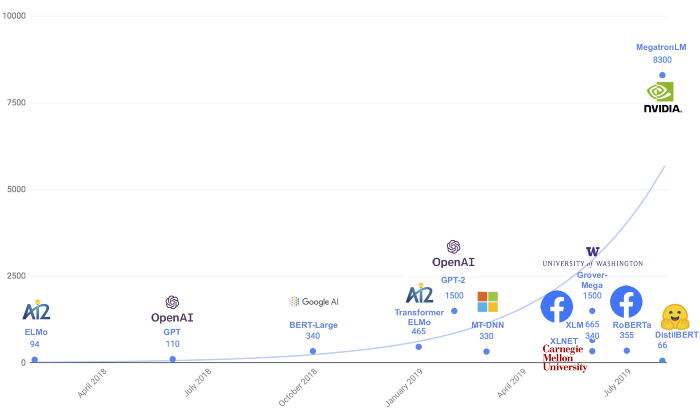
The best known example of this is the DistilBERT model. The DistilBERT model is a smaller version of the large natural-language procession model Bert, which achieves 97% of the performance of Bert while only containing 40% of the weights and being 60% faster. You can see in the figure below how it is much smaller in size compared to other models developed at the same time.
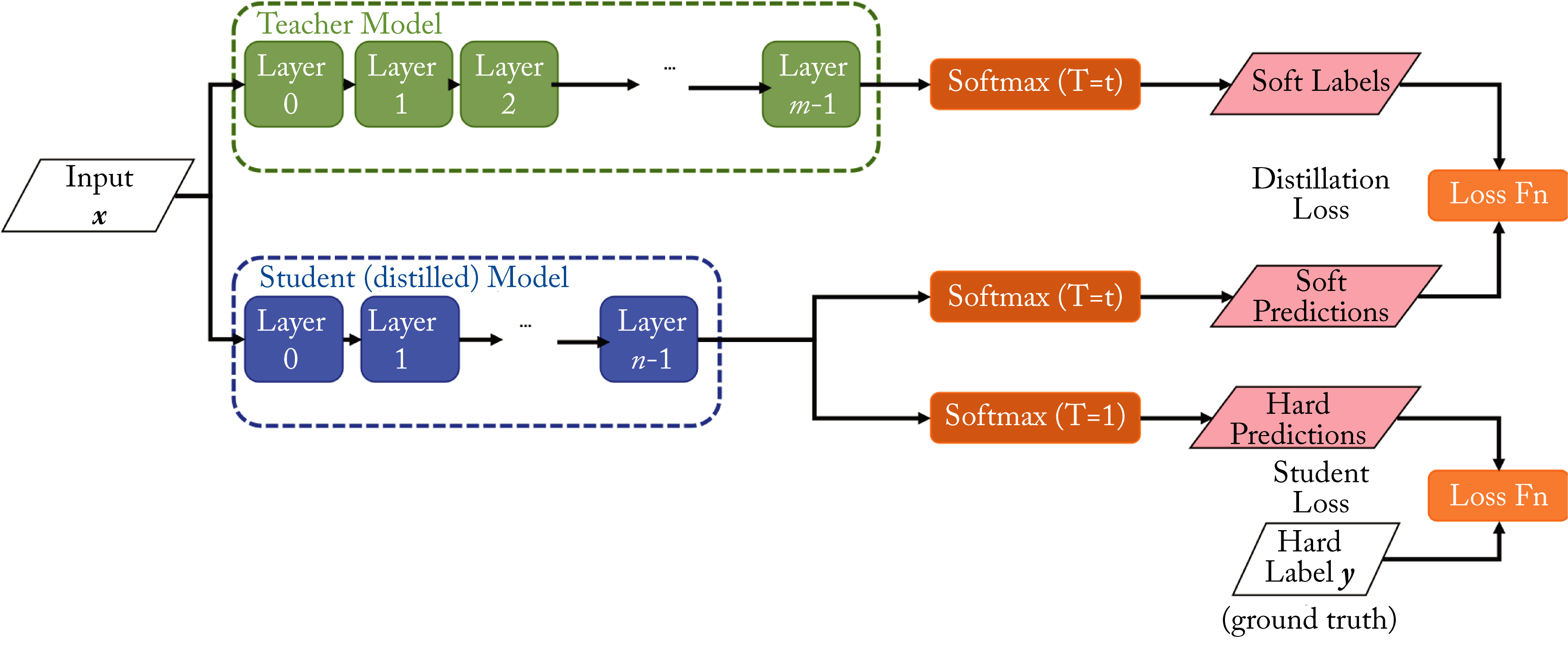
Knowledge distillation works by assuming we have a big teacher that is already performing well that we want to compress. By running our training set through our large model we get a softmax distribution for each and every training sample. The goal of the student is to both match the original labels of the training data but also match the softmax distribution of the teacher model. The intuition behind doing this is that the teacher model needs to be more complex to learn the complex inter-class relationship from just (one-hot) labels. The student on the other hand gets directly fed with softmax distributions from the teacher that explicitly encodes this inter-class relasionship and thus does not need the same capacity to learn as the teacher.
❔ Exercises
Let's try implementing model distillation ourselves. We are going to see if we can accomplish this on the cifar10 dataset. Do note that the exercises below can take quite a long time to finish because they involve training multiple networks and therefore involve some waiting.
-
Start by install the
transformersanddatasetspackages from Huggingfacefrom which we are going to download the cifar10 dataset and a teacher model.
-
Next download the cifar10 dataset
-
Next let's initialize our teacher model. For this we consider a large transformer-based model:
-
To get the logits (un-normalized softmax scores) from our teacher model for a single datapoint from the training dataset you would extract it like this:
sample_img = dataset['train'][0]['img'] preprocessed_img = extractor(dataset['train'][0]['img'], return_tensors='pt') output = model(**preprocessed_img) print(output.logits) # tensor([[ 3.3682, -0.3160, -0.2798, -0.5006, -0.5529, -0.5625, -0.6144, -0.4671, 0.2807, -0.3066]])Repeat this process for the whole training dataset and store the result somewhere.
-
Implement a simple convolutional model. You can create a custom one yourself or use a small one from
torchvision. -
Train the model on cifar10 to convergence, so you have a base result on how the model is performing.
-
Redo the training, but this time add knowledge distillation to your training objective. It should look like this:
-
Compare the final performance obtained with and without knowledge distillation. Did the performance improve or not?
This ends the module on scaling inference in machine learning models.