Project work
Approximately 1/3 of the course time is dedicated to doing project work. The projects will serve as the basis of your exam. In the project, you will essentially re-apply everything that you learn throughout the course to a self chosen project. The overall goals with the project is:
- Being able to work in a group on a larger project
- To formulate a project within the provided guidelines
- Apply the material though in the course to the problem
- Present your findings
In the projects you are free to work on whatever problem that you want. That said, we have a specific requirement, that you need to incorporate some third-party framework into your project. If you want inspiration for projects, here are some examples
We hope most students will be able to form groups by themselves. Expected group size is between 3 and 5. If you are not
able to form a group, please make sure to post in the #looking-for-group channel on Slack or make sure to be present
on the 4th day of the course (the day before the project work starts) where we will help students that have not found a
group yet.
Open-source tools
We strive to keep the tools thought in this course as open-source as possible. The great thing about the open-source community is that whatever problem you are working on, there is probably some package out there that can get you at least 10% of the way. For the project, we want to enforce this point and you are required to include some third-party package, that is neither Pytorch or one of the tools already covered in the course, into your project.
If you have no idea what framework to include, the Pytorch ecosystem is a great place for finding open-source frameworks that can help you accelerate your own projects where Pytorch is the backengine. All tools in the ecosystem should work greatly together with Pytorch. However, it is important to note that the ecosystem is not a complete list of all the awesome packages that exist to extend the functionality of Pytorch. If you are still missing inspiration for frameworks to use, we highly recommend these three that have been used in previous years of the course:
-
PyTorch Image Models. PyTorch Image Models (also known as TIMM) is the absolutely most used computer vision package (maybe except for
torchvision). It contains models, scripts and pre trained for a lot of state-of-the-art image models within computer vision. -
Transformers. The Transformers repository from the Huggingface group focuses on state-of-the-art Natural Language Processing (NLP). It provides many pre-trained model to perform tasks on texts such as classification, information extraction, question answering, summarization, translation, text generation, etc in 100+ languages. Its aim is to make cutting-edge NLP easier to use for everyone.
-
Pytorch-Geometric. PyTorch Geometric (PyG) is a geometric deep learning. It consists of various methods for deep learning on graphs and other irregular structures, also known as geometric deep learning, from a variety of published papers.
Project days
Each project day is fully dedicated to project work, except for maybe external inspirational lectures in the morning. The group decides exactly where they want to work on the project, how they want to work on the project, how do distribute the workload etc. We encourage strongly to parallelize work during the project, because there are a lot of tasks to do, but it it is important that all group members at least have some understanding of the whole project.
Remember that the focus of the project work is not to demonstrate that you can work with the biggest and baddest deep learning model, but instead that you show that you can incorporate the tools that are taught throughout the course in a meaningful way.
Also note that the project is not expected to be very large in scope. It may simply be that you want to train X model on Y data. You will approximately be given 4 full days to work on the project. It is better that you start out with a smaller project and then add complexity along the way if you have time.
Day 1
The first project days is all about getting started on the projects and formulating exactly what you want to work on as a group.
-
Start by brainstorming projects! Try to figure out exactly what you want to work with and begin to investigate what third party package that can support the project.
-
When you have come up with an idea, write a project description. The description is the delivery for today and should be at least 300 words. Try to answer the following questions in the description:
- Overall goal of the project
- What framework are you going to use and you do you intend to include the framework into your project?
- What data are you going to run on (initially, may change)
- What models do you expect to use
-
(Optional) If you want to think more about the product design of your project, feel free to fill out the ML canvas (or part of it). You can read more about the different fields on canvas here.
-
After having done the product description, you can start on the actual coding of the project. In the next section, a to-do list is attached that summaries what we are doing in the course. You are NOT expected to fulfill all bullet points from week 1 today.
The project description will serve as an guideline for us at the exam that you have somewhat reached the goals that you
set out to do. By the end of the day, you should commit your project description to the README.md file belonging
to your project repository. If you filled out the ML canvas, feel free to include that as part of the README.md file.
Also remember to commit whatever you have done on the project until now. When you have done this, go to DTU Learn and
hand-in (as a group) the link to your GitHub repository as an assignment.
We will briefly (before next Monday) look over your GitHub repository and project description to check that everything is fine. If we have any questions/concerns we will contact you.
Day 2
The goal for today is simply to continue working on your project. Start with bullet points in the checklist from week 1 and continue with bullet points for week 2.
Day 3
Continue working on your project, today you should hopefully focus on the bullet points in the checklist from week 2. There is no delivery for this week, but make sure that you have committed all your progress at the end of the day. We will again briefly look over the repositories and will reach out to your group if we are worried about the progression of your project.
Day 4
We have now entered the final week of the course and the second last project day. You are most likely continuing with bullet points from week 2, but should hopefully begin to look at the bullet points from week 3 today. These are in general much more complex, so we recommend looking at them until you have completed most from week 2. We also recommend that you being to fill our report template.
Day 5
Today you are finishing your project. We recommend that you start by creating a architechtual overview of your project similar to this figure. I recommend using draw.io for creating this kind of diagram, but feel free to use any tool you like. Else you should just continue working on your project, checking of as many bullet points as possible. Finally, you should also prepare yourself for the exam tomorrow.
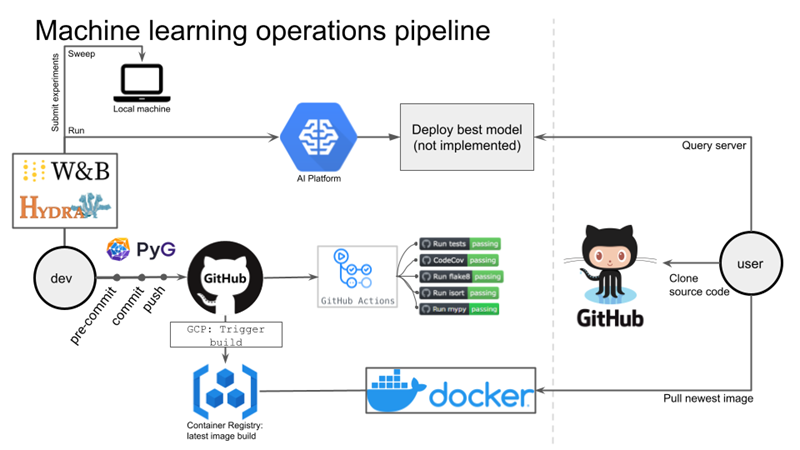{kind=link}
Project checklist
Please note that all the lists are exhaustive meaning that I do not expect you to have completed very point on the checklist for the exam.
Week 1
- Create a git repository
- Make sure that all team members have write access to the GitHub repository
- Create a dedicated environment for you project to keep track of your packages
- Create the initial file structure using cookiecutter
- Fill out the
make_dataset.pyfile such that it downloads whatever data you need and - Add a model file and a training script and get that running
- Remember to fill out the
requirements.txtfile with whatever dependencies that you are using - Remember to comply with good coding practices (
pep8) while doing the project - Do a bit of code typing and remember to document essential parts of your code
- Setup version control for your data or part of your data
- Construct one or multiple docker files for your code
- Build the docker files locally and make sure they work as intended
- Write one or multiple configurations files for your experiments
- Used Hydra to load the configurations and manage your hyperparameters
- When you have something that works somewhat, remember at some point to to some profiling and see if you can optimize your code
- Use Weights & Biases to log training progress and other important metrics/artifacts in your code. Additionally, consider running a hyperparameter optimization sweep.
- Use Pytorch-lightning (if applicable) to reduce the amount of boilerplate in your code
Week 2
- Write unit tests related to the data part of your code
- Write unit tests related to model construction and or model training
- Calculate the coverage.
- Get some continuous integration running on the GitHub repository
- Create a data storage in GCP Bucket for you data and preferable link this with your data version control setup
- Create a trigger workflow for automatically building your docker images
- Get your model training in GCP using either the Engine or Vertex AI
- Create a FastAPI application that can do inference using your model
- If applicable, consider deploying the model locally using torchserve
- Deploy your model in GCP using either Functions or Run as the backend
Week 3
- Check how robust your model is towards data drifting
- Setup monitoring for the system telemetry of your deployed model
- Setup monitoring for the performance of your deployed model
- If applicable, play around with distributed data loading
- If applicable, play around with distributed model training
- Play around with quantization, compilation and pruning for you trained models to increase inference speed
Additional
- Revisit your initial project description. Did the project turn out as you wanted?
- Make sure all group members have a understanding about all parts of the project
- Uploaded all your code to github
Exam
The exam consist of a written and oral element, and both contributes to the overall evaluation if you should pass or not pass the course.
For the written part of the exam we provide an template folder called
reports. As the first task you should copy the folder and
all its content to your project repository. Then, you jobs is to fill out the README.md file which contains the report
template. The file itself contains instructions on how to fill it out and instructions on using the included report.py
file. You will hand-in the template by simple including it in your project repository. By midnight on the 19/1 we will
scrape it automatically, and changes after this point are therefore not registered.
For the oral part of the exam you will be given a time slot where you have to show up for 5-7 min and give a very short demo of your project. What we are interested in seeing is essentially a live demo of your deployed application/project. We will possibly also ask questions regarding the overall curriculum of the course. Importantly, you should have your deployed application, the GitHub repository with your project code, W&B account and your GCP account ready before you enter the exam so we can quickly jump around. We will send out an the time slots during the last week.